本文來自格隆匯專欄:半導體行業觀察
RISC-V這幾年風潮正盛,而RISC-V內核應用最廣的則是MCU。尤其是國內的MCU廠商對RISC-V的追捧程度可見一斑,基本上知名的MCU廠商都有RISC-V的方案。憑藉指令集少、開源等的優點,RISC-V也給了國產MCU趕超國際大廠的機會。但是現在,我們看到,RISC-V的觸角正在不斷蔓延,從最開始的MCU逐漸來到加速器、CPU、AI處理器甚至是GPU。
RISC-V被用作加速器
現在RISC-V越來越多的被用作加速器。歐洲成立的EPI項目的一個關鍵部分是開發和演示基於 RISC-V 指令集架構的完全由歐洲開發的處理器 IP,提供名為 EPAC(歐洲處理器加速器)的高能效和高吞吐量加速器內核。就在近日,EPAC1.0 RISC-V 測試芯片樣品已交付給 EPI 並且其操作的初步測試成功。
EPAC 結合了多種專門用於不同應用領域的加速器技術。下圖所示的測試芯片包含四個矢量處理微瓦(VPU),由SemiDynamics設計的Avispado RISC-V內核和巴塞羅那超級計算中心和薩格勒布大學設計的矢量處理單元組成。每個 tile 還包含一個 Home Node 和 L2 緩存,分別由 Chalmers 和 FORTH 設計,提供了內存子系統的連貫視圖。該芯片還包括兩個額外的加速器:由 Fraunhofer IIS、ITWM 和 ETH Zürich 設計的 Stencil 和 Tensor 加速器 (STX),以及由 CEA LIST 設計的精度可調處理器 (VRP)。片上的所有加速器都與 EXTOLL 的超高速片上網絡和 SERDES 技術相連。

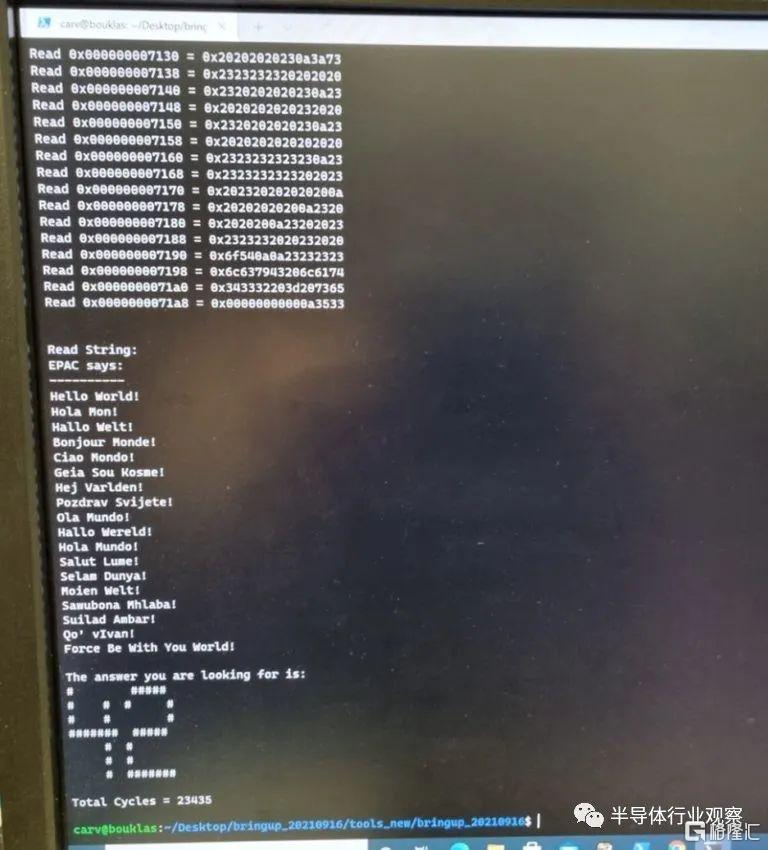
EPAC測試樣品
初始啟動成功,EPAC 執行了它的第一個裸機程序,發送傳統的“Hello World!” 用不同的語言向 EPI 財團和世界致以問候。
成立於2018年的初創公司Ventana Micro Systems 看到了強大的RISC-V服務器業務的窗口。Ventana 創始人兼首席執行官 Balaji Baktha 表示:“近一半的計算支出正在從通用處理器轉向基礎設施計算和特定領域的加速器。“憑藉我們基於可擴展 RISC-V 架構的高性能內核以及我們基於小芯片的快速產品化方法,Ventana 完全有能力利用這一趨勢。”
Ventana公司官網中介紹,其RISC-V內核的性能與高端Arm和x86數據中心內核相當,而且獨特的微架構創新使其設計可在領先的晶圓廠和工藝節點之間輕鬆移植。
據透露,其 64 位RISC-V處理器的首批樣品有望在明年下半年與客户共享,並在2023年上半年量產。據The Register的報道,該公司首席執行官兼聯合創始人 Balaji Baktha介紹到,他們的新芯片採用Chiplet的方式,即每個芯片將包含多個獨立的裸片,包括一些帶有 CPU 內核,一些帶有自定義加速,另一些帶有 IO 和內存接口,然後在單個封裝內互連。所有裸片都使用由Ventana設計的互連連接在一起,據説該互連是緩存一致的,訪問延遲為8ns,並且每條通道最多可移動 16Gbps。這家初創公司認為這將適用於連貫地連接 CPU 內核、加速芯片、片上存儲以及與片外 RAM、PCIe 設備和其他 IO 通信的接口。
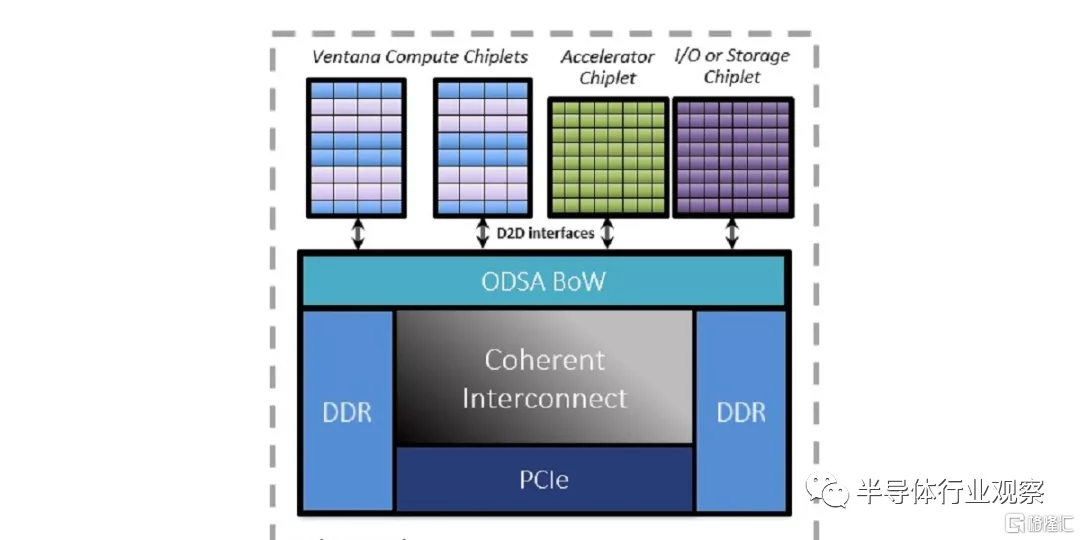
按照他們的規劃,計算和 IO 芯片將由Ventana設計,定製加速芯片將由客户提供,而整個產品由 Ventana 使用其代工廠合作伙伴為其封裝。一個處理器封裝中最多可以放置六個小芯片。客户只需確保自己的定製芯片設計符合互聯規範就可以直接投入使用。
與流行的IP模型相比,Ventana 的模塊化、可擴展的基於小芯片的產品策略可顯着減少開發時間和成本。雖然 Ventana 的計算小芯片通過針對尖端工藝幾何形狀來最大限度地提高性能,但客户可以在目標應用的最佳工藝節點中實施其獨特的 SoC 小芯片硅。為確保互操作性,Ventana 提供了一種並行芯片到芯片 (D2D) 解決方案,能夠實現極低的延遲、高帶寬和最低功耗。D2D 解決方案符合 OCP Open Domain-Specific Architecture (ODSA) 物理接口標準。
預計這些芯片最開始將用於諸如控制和數據平面處理器、安全和存儲設備的片上系統、用於構建大量自己的服務器和數據中心的超大規模企業和類似企業,並希望在芯片級別包含特定功能。根據 Baktha 的説法,這些客户被 RISC-V 吸引的原因是一方面,它允許他們使用自己的自定義指令擴展開放的、免版税的指令集架構,以加速特定任務。
RISC-V來到CPU
在CPU領域的應用,中國可謂是走在前列。首先是阿里巴巴於2019年推出了玄鐵910,根據阿里巴巴集團副總裁戚肖寧博士公佈的資料顯示,玄鐵910基於當下非常熱門的RISC-V開源架構開發,是一款高性能CPU,可以以IP Core的形式集成到SoC處理器當中。
此外,中科院計算所去年發佈了基於RISC-V的香山內核。該內核的第一版微架構雁棲湖在去年6月就建立了代碼倉庫,並於今年四月完成了RTL工作。雁棲湖採用台積電28nm架構,是一個11級流水線的架構,頻率可達1.3GHz,SPEC CPU2006可達7分/GHz左右。第二版南湖架構的設計討論工作也在今年開始,預計2021年底可以完成。該架構採用中芯國際的14nm工藝,頻率預計可以達到2GHz,SPEC CPU2006可達10分/GHz。值得一提的是,基於RISC-V的筆記本有望明年問世。中科院軟件研究所計劃在2022年底之前打造2000台RV64GC筆記本。
作為全球的做大的CPU領主英特爾正在加入這個行列。據知情人士透露,RISC-V初創公司 SiFive已收到投資者英特爾公司的收購意向。據報道,英特爾宣佈將打造自己的RISC-V開發平台,代號為Horse Creek。該芯片有望在 2022 年推出,採用 7nm 工藝。新平台將採用 SiFive P550,這是一種新發布的CPU內核,代表了迄今為止發佈的最高性能 RISC-V CPU。
初創公司也開始參與到RISC-V CPU中來。據SemiAnalysis的爆料,一家名為Rivos的初創公司,正在利用RISC-V研製CPU。這家公司的團隊成員來自蘋果、谷歌、高通、英特爾、Marvel等。SemiAnalysis相信這將是第一個真正高性能的RISC-V設計。
一則蘋果招聘廣吿顯示,蘋果開始對RISC-V感興趣。該公司正在探索使用RISC-V芯片。職位要求“成功的候選人將從矢量編程的角度對 RISC-V ISA 架構有很好的理解和知識,以及 ARM CPU 內核中的 NEON 微架構的工作知識。”

雖然有些人認為這表明蘋果正在尋求更換基於ARM的處理器,但這種情況極不可能,該職位的範圍非常具體。職位描述中指出,程序員將在一個“實施創新的 RISC-V 解決方案和最先進的例程”的團隊中工作。這是為了支持機器學習、視覺算法、信號和視頻處理等必要的計算,”這項工作在 Apple 的 Vector and Numerics Group 內,該集團在 Mac、iPhone、Apple Watch 和 Apple TV 等產品中設計嵌入式子系統。這可能表明 RISC-V 將用於支持硬件,而不是為計算設備提供動力的主處理器。
歐洲甚至成立了兩個關於RISC-V的項目,分別是前文所指的EPI和eProcessor 項目。不同於EPI項目,eProcessor項目旨在構建一個新的開源 OoO 處理器,並提供第一個基於這個新 RISC-V CPU 的完全開源的歐洲全棧生態系統。eProcessor 計劃用於數據服務器、高級駕駛輔助系統 (ADAS) 的人工智能 (AI) 和中央汽車 CPU 以及用於手機和物聯網中的嵌入式應用的CPU。
此外,RISC-V還可以優化CPU和網絡之間絕對時延的確定性問題。斯坦福大學的博士後Stephen Ibanez 在 OSDI '21 會議上提出了 nanoPU 概念。他們提出了一種協同設計的網絡接口卡和 RISC-V 處理器,它提供了一條進入 CPU 的快速路徑,可以顯着降低 RPC 的延遲並同時使它們更具確定性時間。
nanoPU是經過網絡優化的新型CPU,旨在最大程度地減少RPC的尾部延遲。通過繞過高速緩存和內存層次結構,nanoPU直接將到達的消息放入CPU寄存器文件中。通過應用程序的線對線延遲僅為65ns,比當前的最新技術快13倍。nanoPU將關鍵功能從軟件轉移到硬件:可靠的網絡傳輸,擁塞控制,核心選擇和線程調度。它還支持獨特的功能來限制高優先級應用程序遇到的尾部延遲。他們的原型nanoPU正是基於改進的RISC-V CPU。
RISC-V開始強攻AI
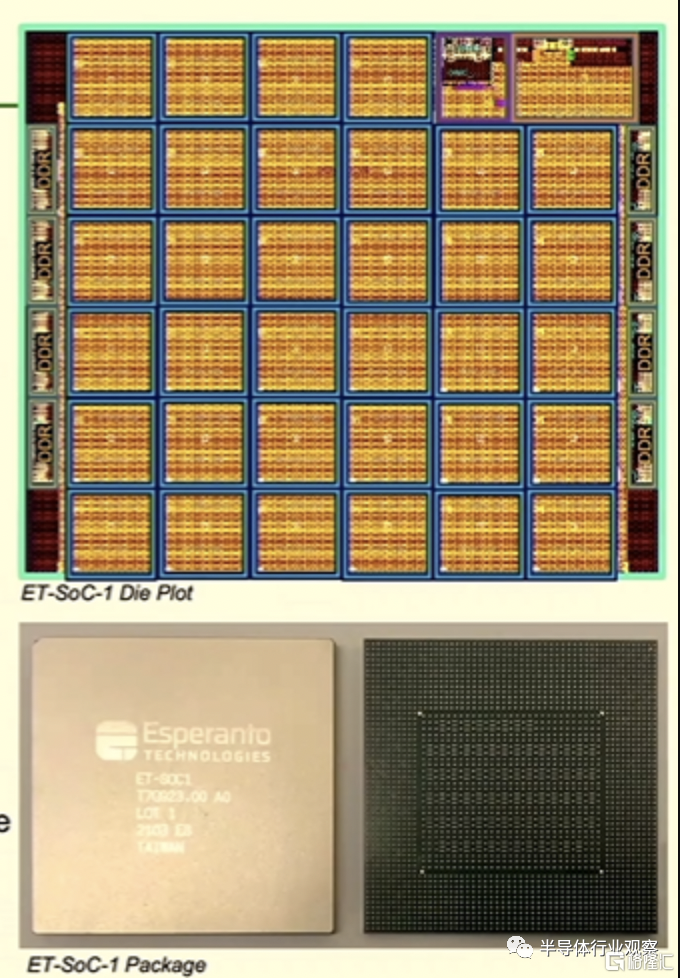
成立於2014年的Esperanto於2020年12月發佈了ET-SoC-1,這是一款基於RISC-V架構的7納米機器學習處理器。該芯片由台積電製造,擁有 2400 萬個晶體管,主要設計用於機器學習推理工作負載。
在最近的 Hot Chips 33線上活動中,Esperanto 創始人兼執行主席 Dave Ditzel 公佈了他所謂的片上超級計算機的詳細信息,它可以用作主處理器或加速器,旨在適應現有的數據中心需要在風冷環境中提高電源效率。
Esperanto 開發的芯片,其中包含 1,088 個節能的 ET-Minion 有序內核,每個內核都帶有一個矢量張量單元,以及四個 ET-Maxion 無序內核。ET-SoC-1 提供超過 1.6 億字節的片上 SRAM、用於具有低功耗 LPDDR4x DRAM 和 eMMC 閃存的大型外部存儲器的接口以及與 PCIe x8 Gen4 和其他 I/O 接口的兼容性。
最重要的是,該芯片可以驅動 100 到 200 TOPS 的峯值速率並以低於 20 瓦的功率運行,這意味着其中 6 個芯片將低於 120 瓦的功率預算。
不同於其他的加速卡解決方案,一個巨大的熱芯片就用盡了加速卡的整個功率預算。Esperanto 的方法是使用多個仍符合功率預算的低功率芯片,隨着更多芯片的加入,性能提高、內存容量增加、內存帶寬增加,低功耗和低成本的 DRAM 解決方案成為實用的解決方案。而RISC-V極簡的指令集架構和邏輯門極少的特點還有助於對電路和架構的更改。
由於 ET-Minion Tensor 內核在最低電壓和 8.5 瓦下運行,Esperanto 能夠在遠低於 120 瓦限制的情況下將 6 個芯片安裝到加速卡中,比單個 118 瓦芯片解決方案提高 2.5 倍的性能功率效率比 275 瓦點高 20 倍。
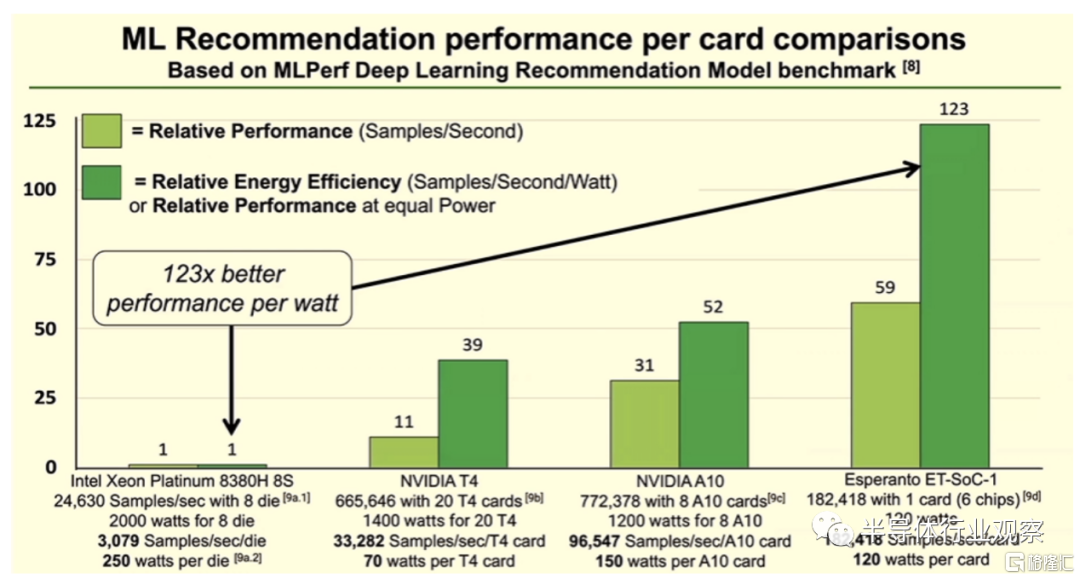
看向最終的性能,在使用MLPerf 深度學習推薦模型與英特爾的八路 Xeon Platinum 8380H 服務器處理器以及 Nvidia 的 A10 和 T4 GPU 的比較中發現,如下所示,Esperanto 芯片的性能是英特爾處理器的 59 倍,是每瓦性能的123倍,並且優於兩個英偉達 GPU。據 Ditzel 稱,類似的結果來自使用 ResNet-50 推理基準。
GPU也有戲?
RISC-V能處理GPU的事務嗎?現在,研究人員研究了一種在名為 Vortex的RISC-V GPGPU 項目上啟用 CUDA 軟件工具包支持的方法。Vortex RISC-V GPGPU 旨在提供基於 RV32IMF ISA 的全系統 RISC-V GPU。這意味着 32 位內核可以從 1 核擴展到 32 核 GPU 設計。它支持 OpenCL 1.2 圖形 API,還支持一些 CUDA 操作。
Nvidia 的 CUDA(計算統一設備架構)代表了一個獨特的計算平台和應用程序編程接口 (API),它運行在 Nvidia 的顯卡系列上。當為 CUDA 支持編寫應用程序時,只要系統發現基於 CUDA 的 GPU,它就會獲得大量的代碼 GPU 加速。
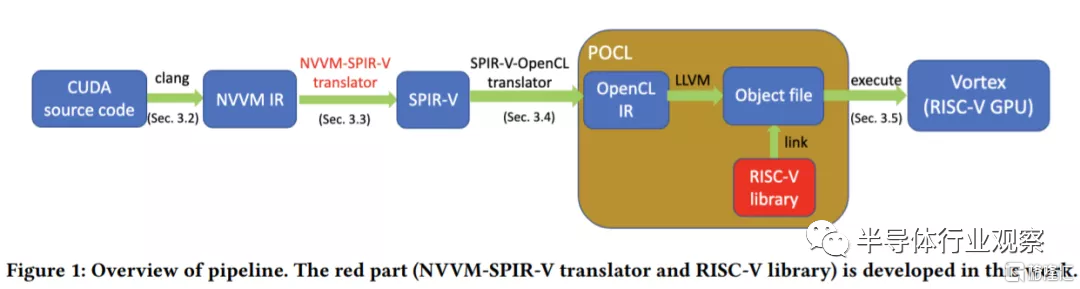
研究人員解釋説:“在這個項目中,我們提出並構建了一個pipeline來支持端到端的 CUDA 遷移:pipeline接受 CUDA 源代碼作為輸入並在擴展的 RISC-V GPU 架構上執行它們。我們的pipeline包括幾個步驟:將CUDA源代碼翻譯成NVVM IR,將NVVM IR轉換成SPIR-V IR,將SPIR-V IR轉發成POCL得到RISC-V二進制文件,最後在擴展的RISC-V GPU上執行二進制文件架構。”
雖然CUDA能夠在RISC-V GPGPU上運行只是一小步,但這可能是 RISC-V 用於加速計算應用程序時代的開始,這與 Nvidia 今天的 GPU陣容非常相似。
結語
綜上來看,RISC-V的更多應用正在被一些初創的企業在探索,RISC-V全面開花的局面或許正在來臨。